The Many Challenges of Shared Memory

The Many Challenges of Shared Memory#
Inter-process communication is the glue that allows multi process applications to share data and coordinate their actions. So any way to improve performance of sending data should be given some attention. Shared memory and the iceoryx2 project promises a great deal of performance gain when it comes to latency between messages sent / received. Actually, it promises zero growth in latency when it comes to any increase in packet size. This is because of how shared memory works - by sending a virtual pointer (more on that later) there’s no need to copy data into a packet to send it out. That means data doesn’t have to be serialized, which also saves some work.

Lord knows I’ve had to do a lot of IPC in robotics. So with ros2 allowing devs to switch it’s underlying DDS middleware to third-party libraries like this one that the creators of iceoryx2 made, this is a promising development.
There are implications beyond the robotics space of course. Less copying to buffers means less memory footprint, which is important for applications running in memory restricted environments such as embedded programming or game dev. And unlike pipes, you can have multiple readers of same data at a time instead of being limited to one reader or sending out multiple copies.
I’ve always wondered that if shared memory is supposedly O(1) speed for getting a message out to another process, why don’t we just use it for everything?
There are things - namely added complexity - that drive a lot of people away from shared memory and keeps it kind of niche technique only used by those that need it. What kinds of problems can you run into though? It helps to understand the details of shared memory before moving on:
First, what is Shared Memory?#
Shared Memory is block of memory two or more applications have access to through memory mapping. The virtual pointer to the data is sent to the subscribing process, the data itself stays in place where it was first allocated.
Without memory mapping, other processes are not going to find the pointer to the memory because the virtual address space is different for each running process. This is done with the mmap function in libc, and that creates a file pointer in the address space of the calling process that can be marked read-only, read-write, or even as executable.
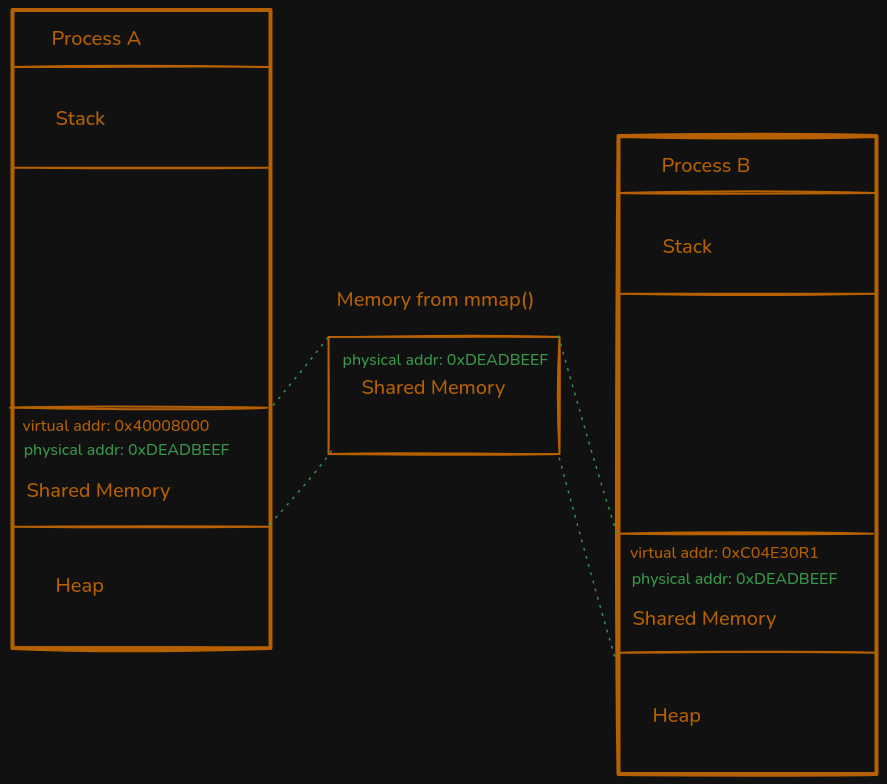
Memory mapping is also key to ensuring safety in the system. If processes crash, the memory should still be cleaned up by a process.
As an aside - memory mapping is itself very useful to know about in terms of reading/writing to files on disk faster. It’s how Apache Kafka writes its gigantic logs in real time.
From there, you create a shared memory object with name and permissions, using shm_open. So you can have a producer/consumer example like below:
Producer
int fd = shm_open("/myshm", O_CREAT | O_RDWR, 0666); // Create shared memory object
ftruncate(fd, SIZE); // Set size of the shared memory
void* ptr = mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// Now you can write to the memory
strcpy(ptr, "Hello from A!");
Consumer
int fd = shm_open("/myshm", O_RDWR, 0666); // Open existing shared memory object
void* ptr = mmap(NULL, SIZE, PROT_READ | PROT_WRITE, MAP_SHARED, fd, 0);
// Now you can read the memory
printf("%s\n", (char*)ptr); // Hello from A!
shm_unlink("/myshm");
Also, don’t forget to free the memory with shm_unlink("/myshm"). It can be
done in either process, probably the consumer in the above simple case.
What happens if the memory isn’t cleaned up?#
Well, that right there is a big part of why shared memory is considered by some to be dangerous.
In linux, the memory will live in /dev/shm/ until you call
shm_unlink("/myshm") delete it explicity with rm /dev/shm/myshm, or on
reboot.
So it’s like a system level memory leak, and trying to resolve this elegantly just adds complexity that probably ought to be handled by a library that has guardrails against things like this happening.
Any other spooky stuff that can happen?#
Oh, race conditions which is inevitable when working with concurrent writers and readers. There are basically two options to prevent them. The naïve approach are locks but now you have a new problem with crashing, leaving a deadlock on process crash. The other option are lock-free algorithms, like iceoryx2 does with lock-free queues. But this is also non-trivial and subtle errors in the lock-free algorithms can lead to data races, which you wanted to prevent in the first place.
Iceoryx2 hides a lot of the complexity that comes with dealing with this, and posts some guard rails to prevent critical errors. It’s fixed-size memory prevents data corruption, and object lifetimes are better handled in it’s native language of Rust.
So what’s the catch, if there is any?#
Obviously there isn’t any benefit to shared memory if you need to send data over a network. But in the case of IPC for processes with access to the same pool of memory, there are still many people using rabbitmq, sockets, and named pipes where shared memory could perform better. So why aren’t devs using it more?
Usually, the cost tradeoff is added complexity. Multiple readers and writers is an advantage - but it could also be a disadvantage if you want to keep the system simple. What you can get away with pipes or sockets, you should.
Conclusion#
So the decision to use shared memory all boils down to needing ultra-low latency, high throughput system, and can accept added complexity and lower crash resilence as the price for speed.
But hopefully, one day, Iceoryx2 and other projects can make low latency communications more accessible and less risky.